业务挑战:互联网交易数据指数级增长,原有数据库性能不足
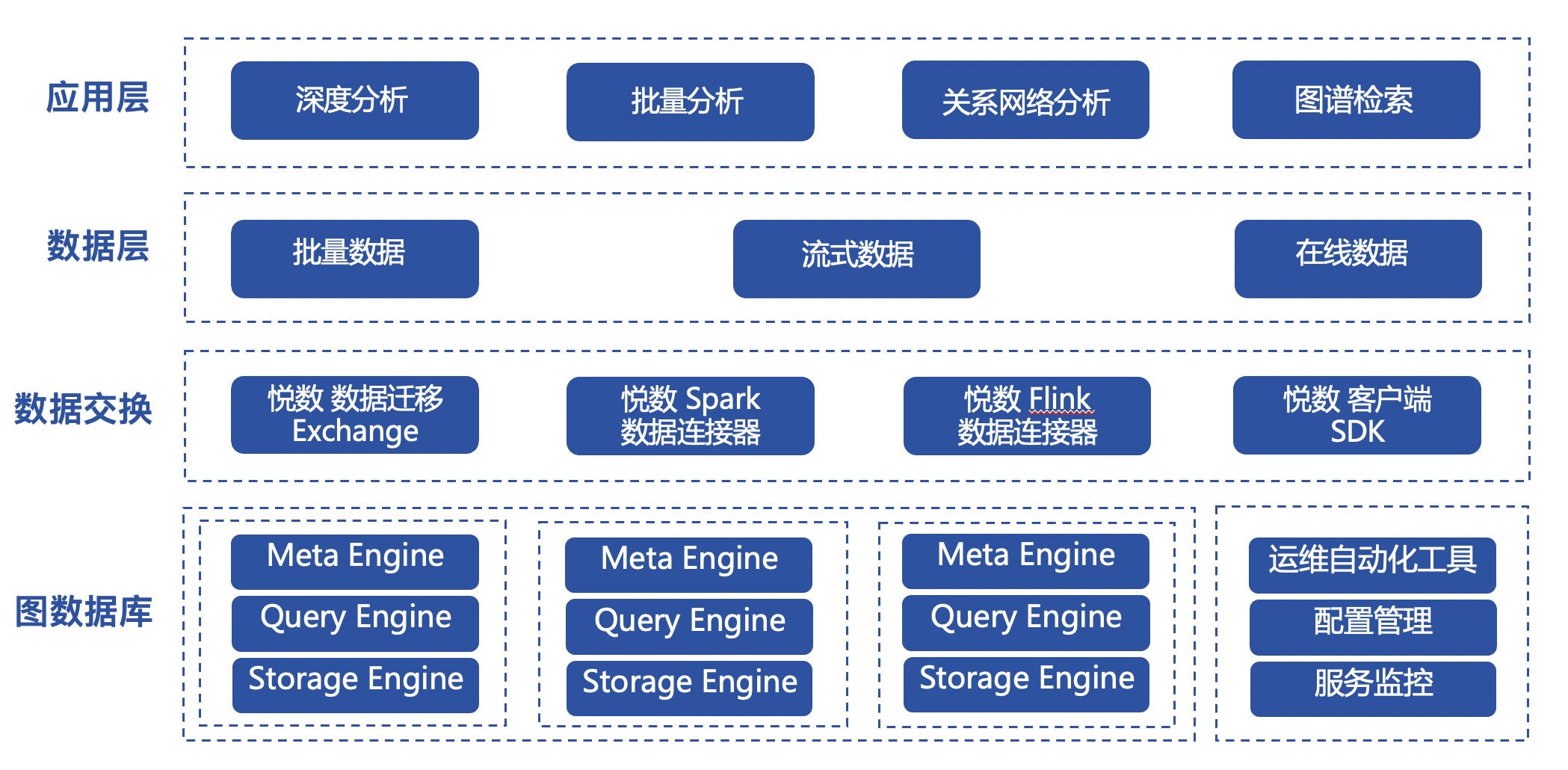
为了应对业务的扩展和数据来源的增长以及指数级增长的互联网金融交易风险,微众银行建立了内部一站式大数据管理平台 WeDataSphere。其基础平台由数据交换、数据分发、计算、存储四大层次组成,关注底层数据传输计算存储能力;功能平台由平台工具、数据工具、应用工具三大层次组成,关注用户各类功能工具需求实现,从而形成完整的大数据平台技术体系,能够提供一站式的丰富数据平台组件及功能支撑。
但早期图数据库系统性能较差,且依赖的其他数据组件较多,运维成本偏高,为提升图数据分析处理的性能和可靠性,计划对当前的图数据库系统进行架构优化。
选择悦数图数据库:建设数据平台分析数据血缘及影响范围
经过测试相较于同类竞品,「悦数图数据库」的查询和导入性能都更优秀。比如 60 万个点、百万级别边这个场景的情况,在单节点低配机器部署情况下,微众银行导入数据基本上在 20 分钟内完成,说明悦数的写入性能非常好。
微众银行在图数据库选型时有一个重量考核点:高可用和容灾的架构支持。悦数图数据库采用分布式设计,支持分集群部署模式,具备存储和计算的横向扩展能力,更加符合银行场景下的分布式和高可用要求。另外,大数据平台本身旨在构建一个完整的数据流生态,悦数提供了丰富的大数据生态工具,包括 Spark/Flink 数据连接器、数据迁移工具等,提供了和大数据平台数据流结合的能力。
应用场景:
应用场景1:血缘数据实时查询
通过建立数据资产目录,指引数据的获取、访问和使用,辅助数据资产的有效利用,实现数据资产安全管理。具体操作来说,可以以某个表为起始节点遍历得到上游表和下游表;服务端通过悦数图数据库的 Java 客户端连接到悦数图数据库查询即可得到血缘关系。
应用场景2:血缘数据批量分析
以某个租户、某个部门的表、某个产品的表为起始节点批量分析得到这些表的上游表和下游表的完整链路;大数据任务通过悦数 Spark 连接器将点数据和边数据批量导入悦数图数据库,再使用基于 GraphX 的算法批量分析得到完整的血缘链路。
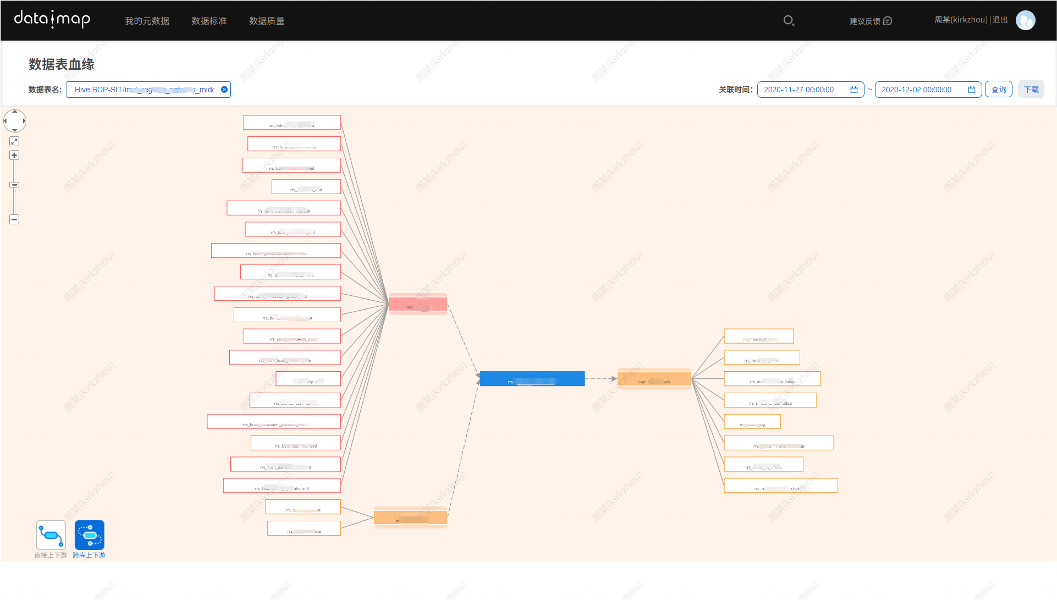
以上图为例,蓝色表为中心数据,通过微众的数据平台可以查询下游的一度关系表和上游的一度关系表。同时大数据平台构建图数据库数据模型时加入了时间属性,因此可以查询特定时间,比如:某张表昨天到今天的血缘关系,用户可基于时间维度进行数据过滤和检索。
使用收益:平台数据治理能力全面提升
通过此次升级,微众银行对大规模数据处理能力得到全面提升。悦数图数据库具备较强的读写平衡能力,同时能达到每秒百万行级的导入能力,实现了数据血缘场景下的实时和批量查询的要求。
其次,悦数图数据库采用存算分离的分布式架构,具备较好的计算和存储层横向扩展能力及金融级高可用能力,能够满足数据和业务动态扩缩容要求,确保集群运行稳定。目前全行 AIOps 都已经接入悦数图数据库平台。
公司介绍
微众银行是中国第一家民营银行,目前个人客户已突破 2.5 亿人,企业法人客户超过170万家。微众银行基于悦数图数据库搭建全行级图平台,并将图指标、图计算纳入风控策略,深度探索潜在的交易风险。
