首页>博客>应用分享>Graph RAG 存知识,DeepSearch 调知识,我们全都要!
Graph RAG 存知识,DeepSearch 调知识,我们全都要!
最近,AI 领域围绕“下一代 RAG 技术演进路径”的讨论逐渐升温。随着大模型应用进入深水区,单纯依赖传统 RAG 的局限性愈发明显——无论是处理千亿级关联数据的效率瓶颈,还是对复杂语义推理的支撑不足,都在倒逼技术架构的升级。
在此背景下,两种技术路径的讨论引发关注:
路径A:知识表示层的革新——通过引入图结构,将非结构化文本转化为可推理的语义网络,解决传统 RAG 的“信息孤岛”问题,典型代表如 Graph RAG。
路径B:检索流程层的优化——通过多轮查询扩展、动态结果重排序等策略提升检索效率,典型方法论如 DeepSearch 范式。
有趣的是,一些讨论试图将两种技术置于“非此即彼”的对立位置,这本质上是混淆了技术层级(知识存储 vs 知识调用)与功能边界(推理增强 vs 效率优化)。
Graph RAG 的不可替代性:从“关联缺失”到“知识穿透”
传统 RAG 的瓶颈在于无法处理非连续、高关联的语义场景,例如:金融风控场景,需追溯企业股权链、担保网络的多层关系;医疗诊断场景,需整合症状、用药、基因突变等跨领域数据。
Graph RAG 的核心优势在于:
知识结构化:通过实体关系图谱构建,将文本转化为可推理的语义网络。
多跳推理:支持从“A→B→C”的链式查询,突破传统 RAG 的单跳检索局限。
动态摘要生成:基于社区检测预生成语义摘要,加速复杂问题的答案生成。
例如,在“光伏产业链竞争分析”场景中,Graph RAG 可自动构建“上游原材料-中游组件-下游电站”的关联图谱,直接定位供应链瓶颈。这种能力是传统 RAG 或单纯检索框架无法实现的。
DeepSearch 的真实定位:检索优化,而非范式颠覆
DeepSearch 的核心价值在于动态优化检索流程,其技术亮点包括:
多轮查询扩展:通过LLM生成补充查询,覆盖用户意图的多个维度。
结果重排序:综合语义相关性、上下文密度等指标筛选最优结果。
混合数据支持:兼容非结构化文本与结构化数据。
但需注意:DeepSearch 并未解决知识关联性问题。例如,在需要跨文档推理“某企业的关联交易风险”时,若底层知识库仍是孤立的文档集合,即使检索效率提升,依然无法生成可信结论。
悦数 Fusion Graph RAG:技术融合的终极答案
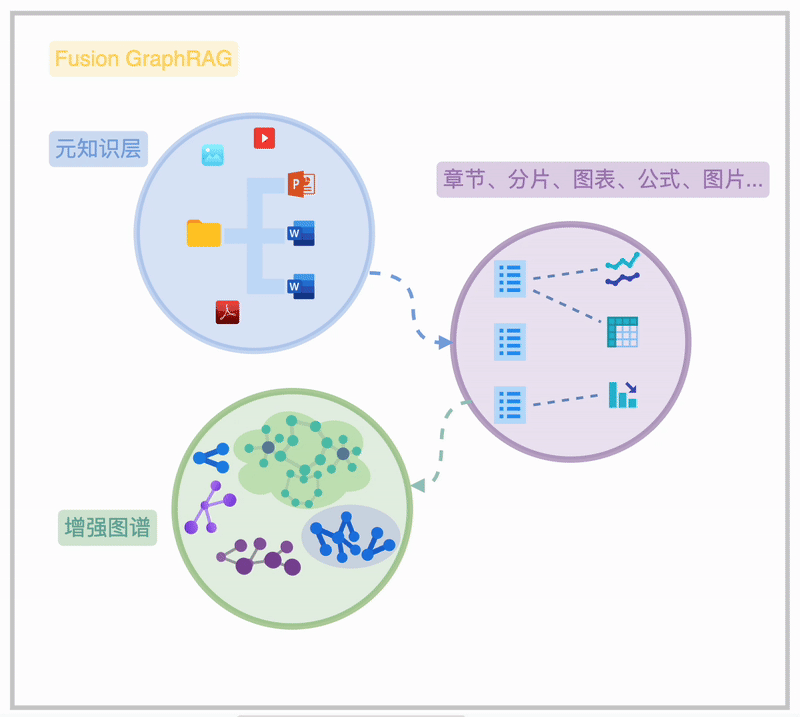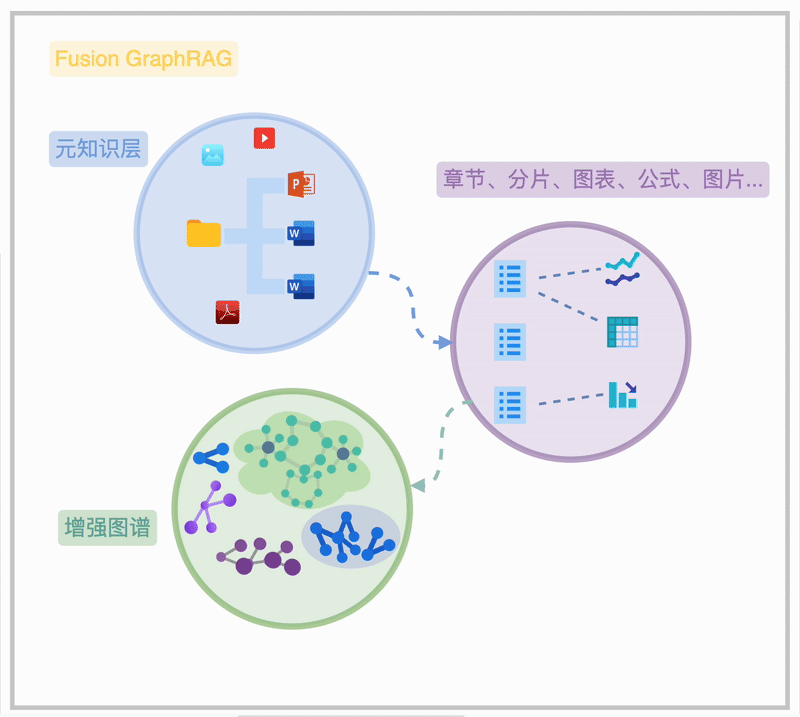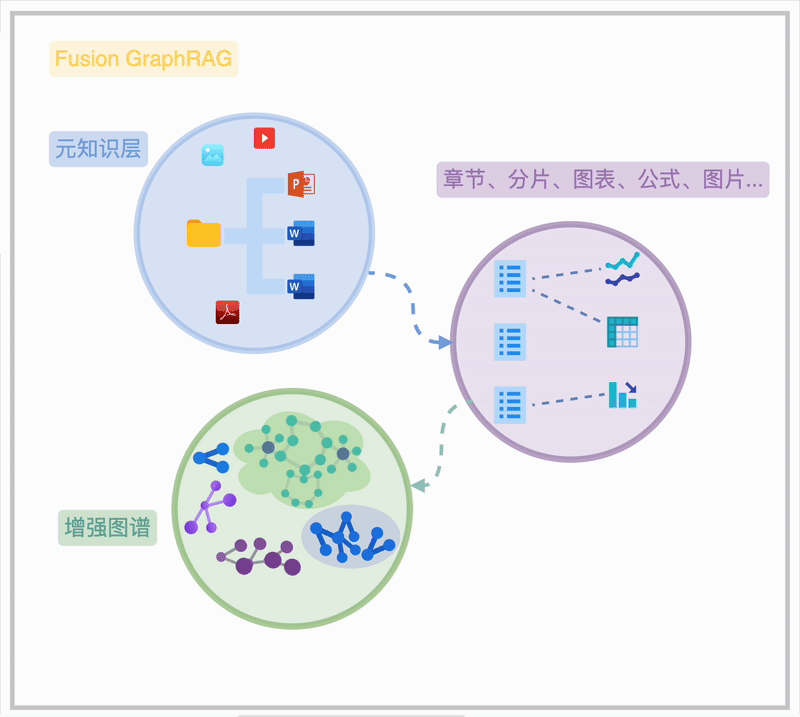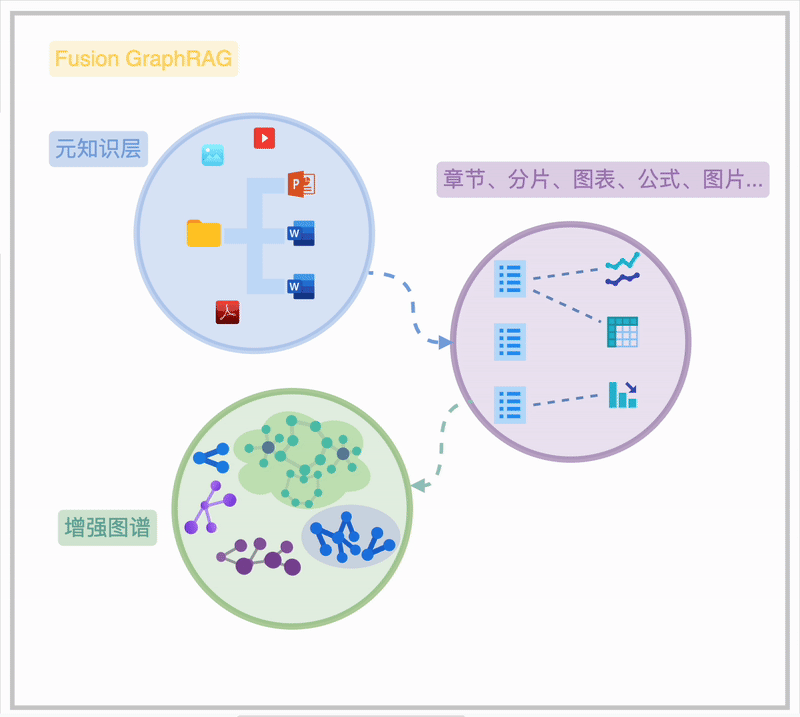
Fusion Graph RAG 是悦数团队在 Graph RAG 基础上的创新实践。它融合了高级 RAG 技术,通过图状结构存储文档层级、章节关系及特殊元素,实现高效、灵活的检索。Fusion Graph RAG 首次实现了“知识图谱”与“动态检索优化”的深度耦合,其架构如图所示:
Fusion Graph RAG 的本质在于 Sota 的高级 RAG 方法融合、充分连接的元知识索引、充分打磨调优的 Graph RAG。
Fusion Graph RAG 通过在一个联通图谱内的“元知识”索引,清晰地揭示海量知识文档的内在关联,呈现从文件夹、文档、章节到段落、图表、公式的完整脉络,此为知识图谱的“元知识频谱”。在此基础上,用户可选择不同粒度的知识抽取方法,构建图谱结构的图索引,形成“增强图频谱”。 进一步,用户可以对图索引和元知识层进行诸如图摘要、权重分配、时序/状语信息补充等增强操作,以提升知识检索和利用的效率。
技术之争的终点是用户价值
真实场景中,客户需求具有双重性:
需求1:快速生成初步报告(DeepSearch 和 DeepResearch 的强项)。
需求2:基于企业知识库的深度推理(Graph RAG 的核心价值)。
Deep Search 和 Deep Research 是毋庸置疑的检索增强,但将其与 Graph RAG 对立,无异于宣称“螺丝刀可替代扳手”。悦数主张分层解耦、融合共生:Graph RAG 解决“知识如何存储”,DeepSearch 优化“知识如何调用”。Fusion Graph RAG 的使命是让企业同时获得“深度”与“效率”,而非在伪命题中二选一。
在 LLM 技术狂飙的今天,真正的创新应是开放整合,而非制造对立。悦数愿与业界共同探索 RAG 的下一站:让知识流动,让价值闭环。



