首页>博客>技术干货行业实践>图 + AI 在金融行业的应用及技术前瞻|应用分享
图 + AI 在金融行业的应用及技术前瞻|应用分享
本文整理自悦数图数据库-资深技术专家-古思为 在《图创价值·图+AI 在金融反欺诈行业应用》现场的分享,查看原文 点击此处。

非常开心有机会跟大家做一个分享。今天的主题是图技术+ AI 在金融反欺诈领域的应用,我的分享内容与之呼应——就是 Graph 和 AI 结合金融领域的一些案例以及最近我们在做的一些大语言模型及前沿技术工具,让我们看看每一个场景里这些新技术能给行业带来什么样的变化。
如何用图的方式做欺诈检测
随着金融业务线上化的普及,现在许多用户会在金融 APP 客户端上申请信用贷款,然后金融机构的系统里面就会关联到申请人的一些信息,比如联系人电话以及工作公司等。首先给大家展示的就是这个线上借贷场景的图模型,目前比较快速直接的方式是把这个问题以图的形式去表达,然后就可以去做一些基础的图模式匹配。
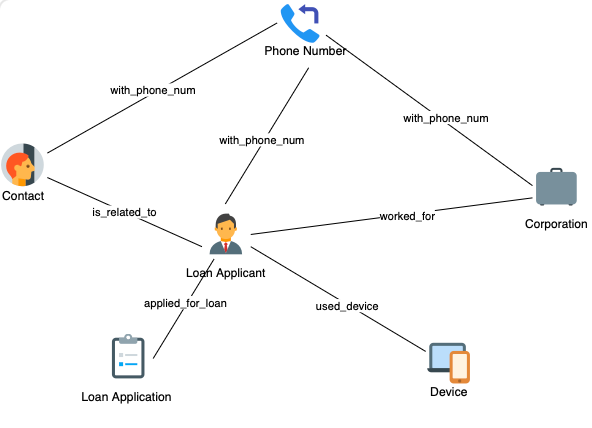
- 线上借贷场景的图模型
另外一个就是用标签传播(Label Spread)的方法去解决其他问题。比如说,从一个点开始找到符合条件的单子,然后我发现他用到了另一个设备,这个设备是跟另一个单子共享的——这个信息如果能够被金融机构以毫秒级的速度获得的话,不仅可以给领域专家拿来做一些及时的洞察分析,而且可以把它放在线上系统里作为提示风险的一个衡量指标。
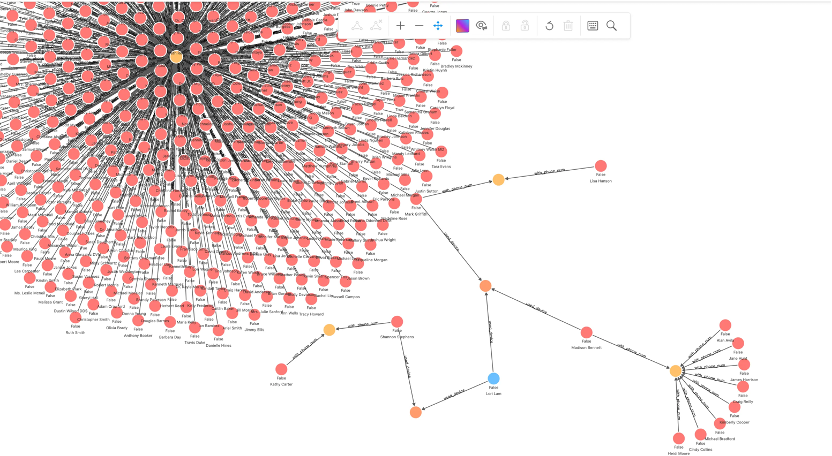
- 通过图查询语句来搜索群控设备
那随之而来就有个问题,如果我们标记的高风险数据量不够的话,怎么能够提高这种特征风控的效果呢?
这里有另一个方法叫「标签传播」(Label Spread)。它其实基本上利用了这个标签传播 Label Propagation 的方法,但这个算法目标有一点变化,我们是想要基于少量标注的有高风险的信息在图上做迭代,类似于标签传播,但我们目的并不是找出社区,而是扩展灰度的标签。这个信息在有时候也是有提示意义的,它可以作为单独的一个参考,给更复杂的风控系统当作一个考量维度。
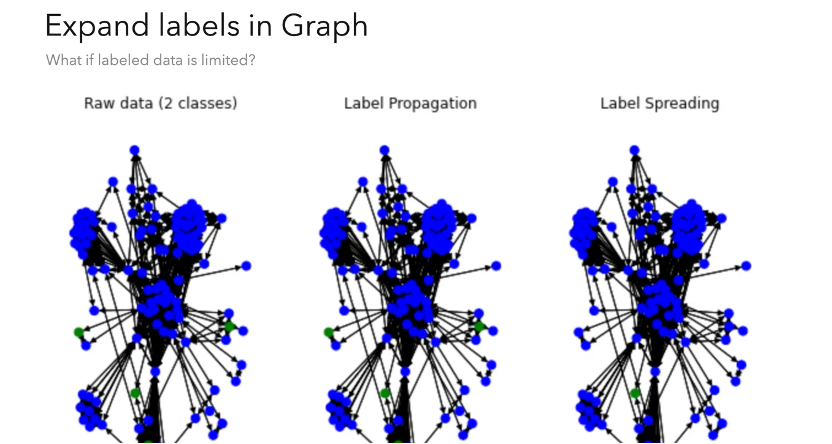
除此之外的话还有一些利用到「机器学习」的方法,最直接也是比较传统的方法,就是纯利用数据属性去做一些分类的模型,然后去定期地识别高风险的交易。当我们把图属性也考虑进来,比如说下面的 Demo,我们可以把社区聚集的信息也作为图特征(Feature)的一部分,我们分出少量的社区,然后把这个社区的数字用 bitwise 的方式把它作为 feature。
我刚刚点了 Louvain 算法之后就可以很清晰地看到有聚集性的集群,不同社区可以使用不同的颜色去区分,这部分信息是可以作为传统机器学习里边的特征考量进来的,因为它体现了一定情况下这些实体之间潜在的关联远近程度,而这个信息在风险预测领域是非常有用的。

除此之外,比如说我们跑一个比较常见的节点重要度算法—— PageRank 算法,就可以看到这里最重要的就是「设备」 这个点跟很多信息都有关联,通过 PageRank 值能够体现节点被连接的程度,这个量化的值作为图特征也是被证明有效的。
另外还有在机器学习领域比较流行的图神经网络(GNN),它是通过一种表示的形式和方法使得图上邻接的关系,以及它在这个函数迭代的过程,能够充分地用点和其他点相邻的关系以及点上属性给体现出来,所以跟之前只是用图特征这几个维度数字作为输入相比,能更好地把图上点与点之间的关系利用起来。
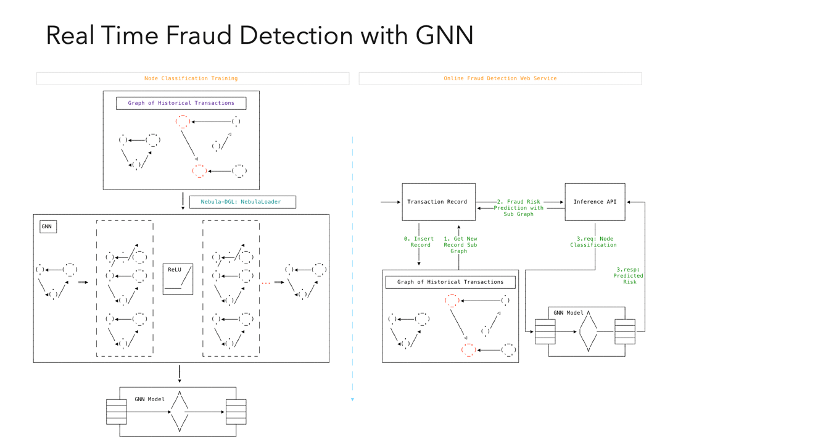
这个例子我之前也分享过,图左边的 GNN 模型是一个节点的分类模型,目标就是预测图上任意一个点是否有风险的分类;右边就是线上系统最后落地的样子。我们建立好图建模信息之后,根据模型里面标注的提示高风险的点进行训练,模型训练好之后输入任意一个子图,它都可以预测出新的子图上任意一个点的风险值,所以在一些金融风控的线上系统中每发现一个新的交易或者是一个请求过来,我们就把这个信息插到图谱上,这样就可以实时进行欺诈检测。
图如何帮助大语言模型的应用落地
第二部分给大家简单介绍一下图(Graph)和大语言模型(LLM)的结合点。
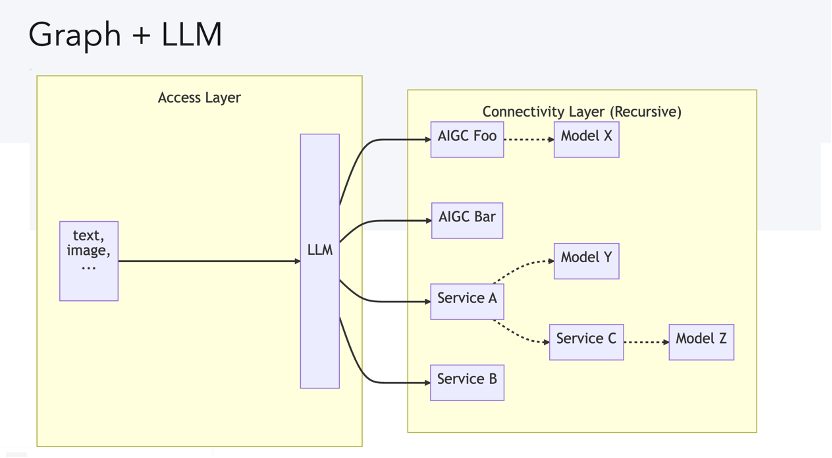
这张图是讲现在我们在大语言模型引领和赋能下可以怎样实现比较智能的图应用。基本上我把它分为接入层和连接层,当然连接层里边是可以迭代的,每个小部分还可以内嵌一个大语言模型,然后提示给大语言模型,比如说 Cloud 或者是 OpenAI 的 GPT 的某一个版本,它就可以理解你的意图,并且直接回答你的问题,也可以根据你的意图再去调用我们已有的其他服务或者模型。
如果你想要做一些创造性的探索,它就可以帮你调某一个生成模型,比如说你想做某个服务的查询,那像 OpenAI 有 API 或者是你自己用一些方式就可以去访问互联网。有了大语言模型这一层,使得以前比如专门做 NLP 或者翻译等等很多以前看起来很难被智能化又非常昂贵的领域,现在都有了更多的备选方案。
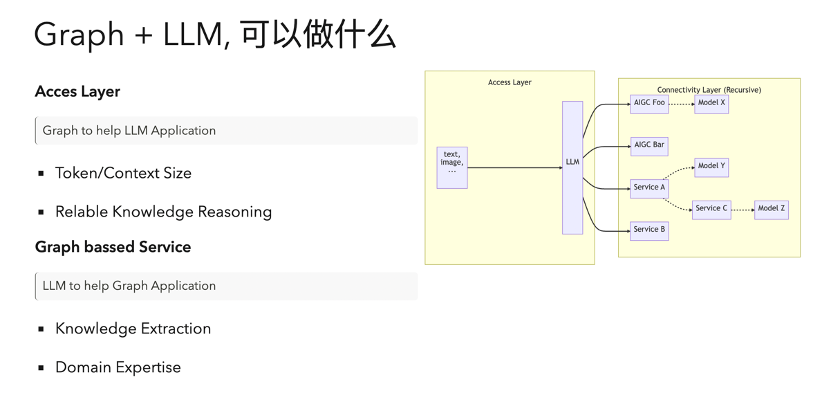
在这里,图数据库可以做什么?
首先,我们可以在接入层做一点事情。比如说我们想要在既定的一个大语言模型上做给定领域的知识问答,一个常见的情况就是我们需要额外同步专有的领域知识,但是这个同步是有限制的,不是所有模型都支持,而且有的时候比较昂贵。比如说我们要基于一个 100 兆的 PDF 作为上下文的背景知识来问问题,常见的方式就是把它给分割开来,比如说分成 100 份,然后每份的内容把它总结起来,然后放在 Vector search 里面做一个嵌入。
具体落地来说,比如你问一个问题,他会把这个问题跟你分割的每一个小块的信息在向量空间里做一个距离的搜寻,取出离得最近的比如三块的相关上下文内容,而把这个上下文和你这个问题一起丢给大语言模型——这是现在最直接的一个方法,但是它还是有问题。
首先就是这种方法虽然缓解了上下文过多的问题,但是也会丢失部分你要额外增加的背景知识,而且你缺失了节点与节点之间的关联,是个割裂的知识块。
其次,我们知道大语言模型有时候的回答不是稳定和可重现的,也不是那么专业可信。举个例子,如果我们想要做一个在医院里处理分诊问题的智能问答机器人,这种情况下即使用非常智能的大语言模型,哪怕只有万分之一的可能会给出很奇怪的结果,所带来的负面影响都是不能承受的——因为它会影响人的生命和健康。这种领域的话,传统方法其实是利用专业的知识图谱(Knowledge Graph)基于基本的模式匹配之后给出一个确定的推理。
这时候就可以用图(Graph) 去解决刚刚提到两个问题,一个是当我们用 Vector search 去做切分的时候,我们可以利用知识图谱提供全局视野。另一个就是我们在基于某个非结构化的海量上下文做问答的时候,比如说一个很大的网站和文档知识库,同时接入已有的知识图谱话,就可以提供一个相对来说比较高可信度的推理。

这个图就是刚刚我提到的知识嵌入(embedding)部分引入图技术, 另一部分其实大语言模型本身是可以帮助图的,就是我们去设置一个知识图谱的时候,知识的梳理其实有时候是涉及到理解力的,这个时候大语言模型是能够起到帮助作用的,而且有时候能够替代一些以前必须得要领域专家引入的环节,相对来说更加的高效和自动化。
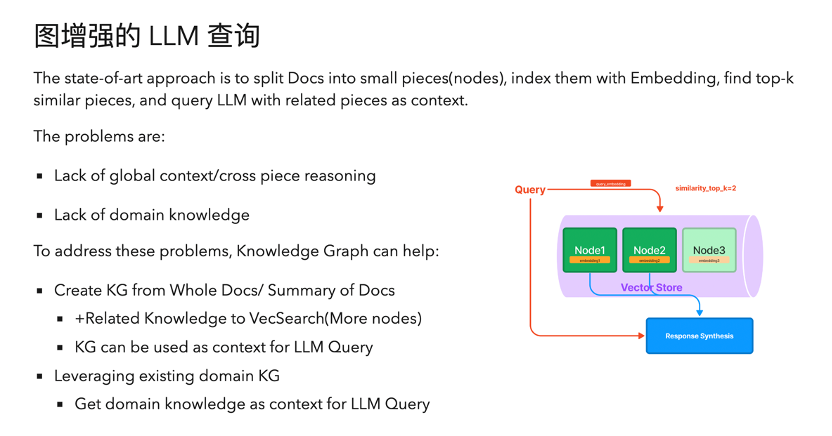
关于前面提到的大语言模型的查询层,实际上这个领域来说,到今天比较先进的方式是有一些人做了一些封装,当然你可以自己直接从头写代码去,中间只要插一个 Vector search 就能做 embedding 的事情。但是有些 dirty work 需要你额外去做,其实大家都做重复的一块。再一个就是有的时候它中间不只是仅仅的去分割然后抽取,其实这是大体的思路,但实际上落地的时候会有很多小的细节的优化途径,所以这个领域其实有一些抽象的中间层的库,比较流行的,比如叫 Langchain 的一个项目。
其次还有个项目叫 LLAMA Index,大家感兴趣的话可以去了解一下,基本上我给 LLAMA 外部知识图谱这个概念,它能够在建立正常的设置参数的过程中,同步地把信息里边的知识总结出来,然后导入到外部的知识图谱中去。
另外,大语言模型也可以帮助很多系统去掉昂贵的人力投入环节。这里边有几个方面,一个是在知识抽取的过程中,我受到启发很有名的项目叫 GraphGPT。基本上我就告诉大语言模型,你现在要帮我做一个知识解析的过程,就是你要从这一段文字里面解析出主谓宾的知识结构。在这个案例里,我给他了一段关于哈利波特的文字,最后他就帮我返回了一个一段 Json,就描述了这一段话里面的三元组的知识。最后我们把它渲染出来,就是一个关于哈利波特的知识图谱。

这只是一个很小的 demo,但图谱其实表现地也很自然,大家只要做图都会想到用大语言模型建立一个知识图谱,现在跟以前的情况和需要的投入完全不同了。
另外一个大语言模型帮助到图(Graph)的一个例子是是我另一个项目,这个项目写得很早,基本上就是你提供给我图上的 schema 以及你想要做的 query,它就可以帮你实时的去写图数据库的查询。
当然了,未来这些能力都会嵌在我们「悦数图数据库」各种各样的产品里,也是蛮有意思,大家如果感兴趣的话,可以找这个 Demo 玩一下。

最后我想说其实图天然是有可解释性的,举个例子,这个是我的另一篇文章里边的例子,但是这个系统是一个推荐系统。我们知道上个礼拜 OpenAI 有篇文章讲他们怎么利用 GPT-4 去为他们的 GPT-2 模型做模型里的可解释性的分析,还挺酷的,其实利用图的话也可以做一定的努力。
这个例子,其实就是我们一个很黑盒的推荐系统给出的结果,只要有这个结果里面涉及到实体做一个路径查询,我们通过图数据库是可以给出一定的可解释性的,蛮有意思的。
悦数图数据库:打造更顺滑高效的 Graph + AI 工具链
最后一部分给大家介绍 Graph + AI 时代,悦数会打造怎么样的产品以及能提供什么样的方法论。
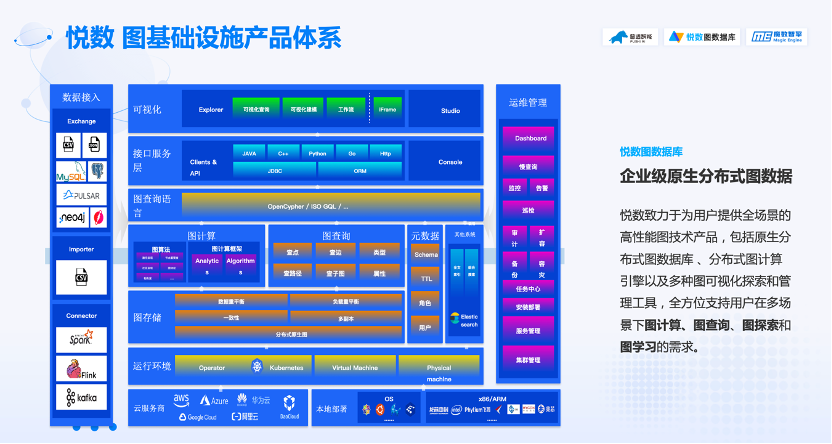
首先,悦数图数据库是原生分布式的,所以你可以很轻松地实时处理很大的数据集群。因为本质上,悦数图数据库的计算与存储是分离的,它的计算层是无状态的,这使得我们做了很多不同的计算层,其实对于图来说都只是另一个异构的查询或计算层而已,因此它的可扩展性非常好。
除了内核数据库之外,悦数还提供了自研的图算法工具,我们可以在这上面自己实现或者是跑现有内置的各种图的算法,目前也很受大家欢迎。其中「悦数图分析」是我们推出的一个图算法工具,这个是只有企业版本。它主要的优势是有更高的资源使用率,然后性能也会更好一些。
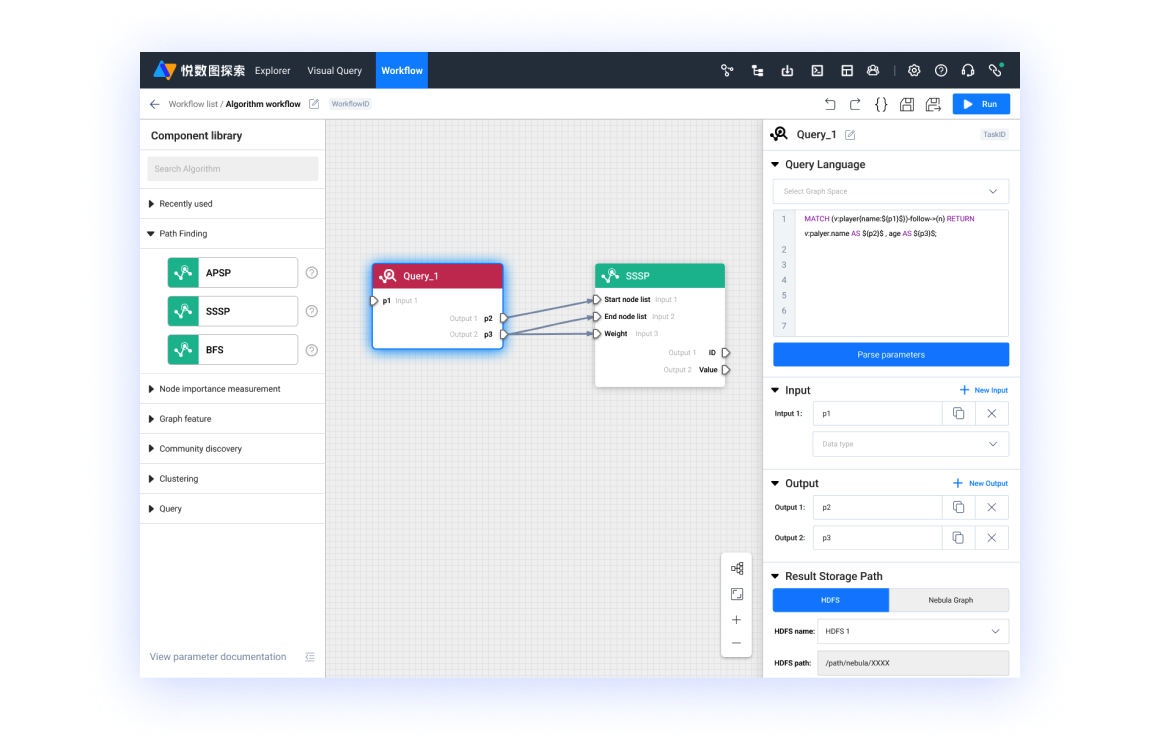
- 悦数可视化产品中的工作流操作展示
「悦数图分析」还有一个优势就是它能跟我们的可视化的工具有非常好的结合。刚才给大家演示的 Demo 就是在悦数的可视化工具里边实现的。大家可以利用工作流快速去验证一个想法,之后再在数据规模更大的情况下再进一步去做 Benchmark 或验证,最后落地到真实的场景。比如这一步取什么样的数据/怎么取,下一步做什么样的运算,这一步运算的输出和另一个运算输出指向下一个任务后再输出到哪里,这些过程在悦数的工具体系里都可以拖拉拽、零代码地实现。
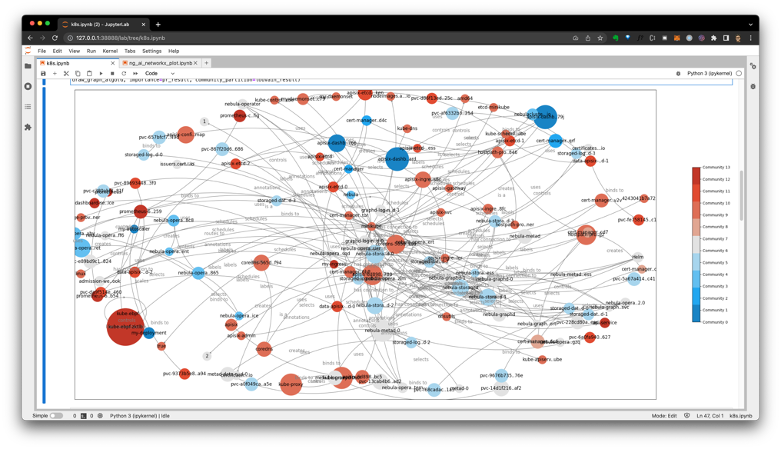
- 基于 AI 工具生成的可视化图数据集
然后,悦数也在做一些跟 AI 以及 GNN 结合的工具类产品。在这里给大家介绍的一个项目叫「AI Suite」,它其实是一个面向 Graph 和 AI 的一个 high level 的 API,它是个 Python 的库,通过几行代码就可以把悦数图数据库上的信息读到这个图里边,然后紧接着像这两行就直接跑了一个 PageRank 算法,然后 AI 工具就可以自动把它画出来。
另外还有跟最流行的两个图神经网络(GNN)的框架之一,亚马逊和纽约大学开源的图深度学习框架 DGL 合作的项目,你可以很容易地把悦数图数据库里面的图给它序列化成 DGL 的对象,然后在此基础之上就可以很容易地做,比如说链路的预测、节点的分析等等。比如说我训练好链路预测的模型之后,取一个点和跟它没有相连的点,然后把数据这个喂给模型就可以做预测,比如某个人有可能想要看哪个电影,也是一个蛮有意思的一个工具。
以上就是我分享的内容,感谢大家的时间,欢迎大家关注我们的公众号和官网,目前悦数图数据库在阿里云上支持 免费试用,欢迎大家进一步了解,谢谢。



